The Evolution of Modern Information: Beyond the Relational Database Myth
We have been lied to for decades about data maturity. Corporate IT departments spent billions during the late 1990s and 2000s building rigid relational database management systems, convinced that everything worth knowing could fit neatly into a spreadsheet row. That changes everything, or at least it did when the internet exploded into a multimedia wilderness. Today, over 80 percent of enterprise data is entirely unformatted, a sprawling mess of audio files, sensor logs, and security video footage that mocks traditional SQL queries. The thing is, companies keep throwing money at legacy storage architectures while expecting modern machine learning insights.
The Real Velocity Problem in 2026
It is not just about size anymore. I watched a logistics firm in Chicago collapse under its own telemetry feed last winter because their engineers treated real-time IoT pings like a batch-processed payroll ledger. What are the four types of big data if not a map of how fast information mutates? Experts disagree on the exact threshold where data becomes "big," but when your ingest pipeline handles 50,000 events per second, standard validation protocols break down entirely. Honestly, it's unclear whether current cloud computing paradigms can sustain this trajectory without widespread adoption of edge computing nodes.
Why the Traditional Three Vs Definition Failed Us
Volume, velocity, and variety were fine for a 2011 whitepaper, yet they fail to capture the operational friction of modern data lakes. The issue remains that data variety has mutated into a spectrum of structural complexity rather than distinct buckets. When a single autonomous vehicle generates 4 terabytes of operational telemetry daily, it mixes structural coordinates with unstructured video feeds. We must classify data by its internal organization, because that determines the computational cost of extracting a single dollar of value.
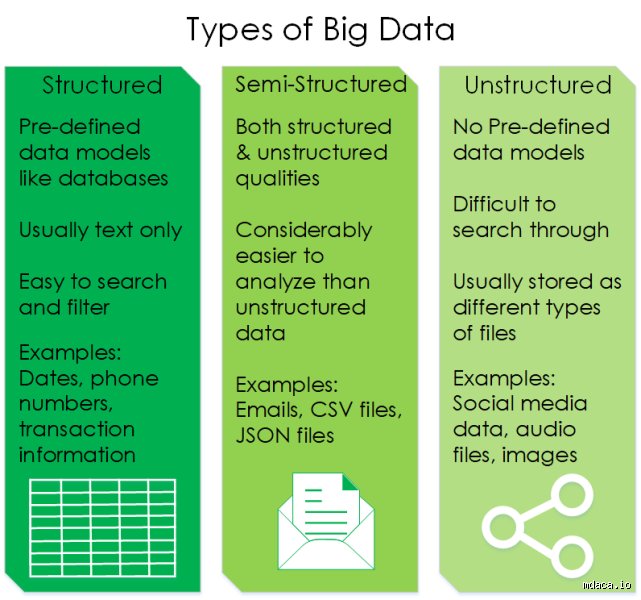
Type 1: Structured Data and the Reassurance of the Grid
Structured data represents the comforting, highly organized minority of the digital universe. This information conforms to a strict, pre-defined schema, typically managed via SQL databases where every data point occupies a specific table cell. Think of an OLTP system at Walmart tracking a Mastercard transaction at a specific register in Miami on October 12, 2025. Because the format is rigid, search algorithms can find specific records in microseconds. But where it gets tricky is assuming this predictability implies superior business intelligence.
The Mechanics of Pre-Defined Schemas
Data engineers refer to this architecture as schema-on-write. Before a single byte touches the solid-state drives, the database engine enforces strict compliance with data types—integers, dates, varchar strings—which explains why financial institutions guard these systems so fiercely. If a transaction amount lacks a decimal point, the system rejects it outright. This structural purity allows for massive scaling through normalization, a process that minimizes redundancy but strips away the messy context of human behavior.
The Hidden Costs of Relational Rigidity
What happens when your business model changes overnight? Imagine you run an e-commerce platform and suddenly need to track user eye-movement telemetry alongside their purchase history. In a structured environment, modifying the database schema requires altering tables with millions of existing rows, a terrifying operational bottleneck that can cause hours of catastrophic downtime. And because these systems cannot ingest unformatted text, they are completely blind to customer sentiment or social media chatter.
Type 2: Unstructured Data and the Wild Digital Wilderness
Now we enter the realm of the digital hoarding crisis. Unstructured data has no predefined conceptual structure, making it completely incompatible with traditional relational tables. People don't think about this enough, but every PDF report, Zoom call recording, satellite image, and corporate email belongs to this category. It is a massive, dark continent of information that grows at an annual rate of 55 percent, threatening to overwhelm corporate storage budgets without offering an obvious path to monetization.
The Chaos of Multimedia Ingestion
How do you extract a trend from a 4K video file? You don't, at least not without heavy computational lifting from deep learning models. When a streaming service like Netflix analyzes viewing habits, they are not just looking at a timestamped click. They are processing thousands of hours of video files, looking for color palettes, audio frequencies, and facial expressions. The data is rich, messy, and fundamentally heavy. As a result: companies pour millions into massive Amazon S3 buckets, creating digital swamps where data goes to die because nobody knows how to index it.
Natural Language as a Data Processing Nightmare
Human speech is the ultimate unstructured variable. A single customer service email contains sarcasm, slang, typos, and cultural nuances that defy basic keyword searches. When analyzing what are the four types of big data, recognizing the raw complexity of human text is critical because it requires a completely different infrastructure—such as NoSQL document stores and Natural Language Processing pipelines—to extract even a shred of operational utility.
Navigating the Gray Zones: Semi-Structured and Quasistructured Realities
The world is rarely binary, which is why the boundary between rigid grids and digital chaos is populated by hybrid data formats. Semi-structured data does not fit into a relational database, yet it contains internal markers, tags, or organizational elements that separate data pieces. This is where we encounter XML files, JSON logs, and NoSQL databases. It is the operational backbone of modern web applications, allowing for flexible data exchange without the bureaucratic nightmare of a fixed database schema.
JSON, XML, and the Power of Self-Description
Consider a standard web API response tracking a user profile. The data contains tags like "userID" or "purchaseHistory" which allow the receiving system to parse the information on the fly. This schema-on-read approach means the data carries its own instruction manual. It allows developers to add new fields—like a user's favorite color or secondary phone number—without breaking the entire system, a flexibility that traditional SQL databases simply cannot offer without complex migration scripts.
Quasistructured Data and the Clickstream Trail
Then there is quasistructured data, a term that makes some purists uncomfortable but remains vital for digital marketing. This refers to textual data with erratic formatting that can be organized with significant effort and tools. Look at a server log file generated when a user navigates a website. It is a dense, chronological string of IP addresses, URLs, timestamps, and browser strings. Except that the formatting varies depending on how the user interacted with the page, making it a frustrating puzzle for data scientists trying to map out a clean conversion funnel.
Navigating the Blind Spots: Common Misconceptions Around Data Typologies
You have likely memorized the quartet of volume, velocity, variety, and veracity. But let us be clear: categorizing data into rigid silos often breeds operational paralysis. The first trap is assuming these boundaries are cast in stone. They are not. A chaotic stream of unstructured social media text does not just sit there waiting for a linguist; modern natural language processing pipelines instantly quantify it, transmuting it into structured sentiment scores. It mutates.
The Trap of the "Unstructured" Myth
Is unstructured data truly devoid of architecture? Absolutely not. Server logs, often tossed into the unstructured bucket by casual observers, actually contain highly predictable timestamps and IP addresses. Labeling 80% of enterprise data as completely unstructured is a lazy generalization that stalls architecture design. The issue remains that teams over-invest in specialized, hyper-segmented storage tools when a unified lakehouse format could handle the fluid spectrum of what are the four types of big data with far greater agility. Why build four separate pipelines when data constantly changes its state?
Equating Volume with Direct Business Value
Size does not guarantee insight. We have witnessed enterprises hoard petabytes of semi-structured clickstream data, praying for a miracle. Yet, 93% of collected corporate data sits dormant as "dark data," costing fortune-level maintenance fees while yielding zero actionable intelligence. Data variety is far more predictive of analytical breakthroughs than sheer mass. If you are merely multiplying the same flat database rows, you are not scaling your intellect; you are just inflating your cloud storage bill.
The Hidden Vector: Behavioral Data Fusion
Here is a piece of expert advice: stop treating the four pillars as distinct buckets and start focusing on their intersections. The real magic happens when you overlay structured transactional records with unstructured biometric or geospatial streams. This synthesis creates what data scientists call a behavioral graph.
The Power of Cross-Pollination
Consider predictive maintenance in aerospace logistics. An isolated sensor reading means very little. But when a 500 Hz vibration stream (unstructured/semi-structured) is correlated with a historical maintenance ledger (structured) and real-time weather telemetry, anomalies leap out. Predictive accuracy spikes by up to 37% when algorithms are fed these blended structures rather than isolated streams. What are the four types of big data if not mere ingredients for a grander, contextual stew? You must engineer your ingestion layers to look for the connective tissue between these formats, rather than segregating them into distinct engineering departments (a common organizational failure that costs millions in lost velocity).
Frequently Asked Questions
Which of the categories poses the highest financial risk if mismanaged?
Unstructured data undeniably claims this hazardous crown because its lack of inherent formatting makes compliance auditing a nightmare. Consider that GDPR violations carried a maximum penalty of 20 million Euros or 4% of global turnover, a blade that falls swiftest on companies oblivious to the Personally Identifiable Information hidden inside raw text files and customer service call recordings. Because these files are incredibly dense and unindexed, standard security scripts fail to flag exposure points. As a result: organizations routinely back up massive, unregulated data dumps into secondary cloud regions, unknowingly multiplying their surface area for devastating ransomware attacks.
How does the rise of Edge Computing alter our understanding of what are the four types of big data?
Edge computing completely shatters the traditional model by processing diverse streams right at the local sensor level instead of centralizing them. Because processing happens locally, raw semi-structured device logs are immediately stripped of noise, transforming into compact, structured alerts before ever touching the corporate cloud network. This shifts the architectural burden away from massive, central data lakes. But the problem is that it requires intelligent, low-latency filtering software deployed on millions of remote micro-nodes, which explains why firmware security has suddenly become the bottleneck of modern information architecture. Will cloud repositories become obsolete? Not quite, yet their primary role is undeniably shifting from active processing hubs to long-term historical archives.
Can small businesses leverage these architectures without million-dollar budgets?
The democratization of open-source cloud frameworks means infrastructure cost is no longer a valid excuse for inaction. Serverless analytical engines allow a five-person startup to parse terabytes of semi-structured JSON payloads for less than the price of a daily espresso. The barrier to entry has completely flipped from financial capital to intellectual capital. In short, success depends entirely on your team's ability to map business questions to the appropriate storage format, proving that data literacy beats raw computing budget every single time.
Beyond the Quad-Fold Taxonomy: A Manifesto for Real-World Architecture
Let us stop treating this foundational framework as an academic dogma to be checked off in a board presentation. The four dimensions of data are not separate planets; they are merely different perspectives of the exact same digital footprint. If your engineering organization is still divided into the "structured SQL team" and the "unstructured NoSQL team," you are actively burning capital. Winners optimize for continuous data mutability. We must build fluid, multi-modal pipelines that expect data to shift from chaotic streams into rigid tables and back again seamlessly. Take a stand, dismantle the internal architectural silos, and realize that value is only extracted when these types collide.