The Evolution of Educational Metrics: Why What Are the Six Principles of Assessment Still Matters Today
Assessment isn't just about handing out a final grade at the end of a grueling semester; it is an ongoing diagnostic conversation. Decades ago, psychometricians at institutions like the Educational Testing Service in Princeton, New Jersey, viewed testing through a clinical, almost punitive lens. But everything changed when classroom demographics shifted. Today, we understand that traditional testing often measures socio-economic privilege rather than actual cognitive growth, which explains why the foundational architecture of evaluation required a massive overhaul. Yet, the issue remains that many districts still rely on outdated Scantron models developed in the late 1970s.
Unpacking the Definitions Beyond the Textbook
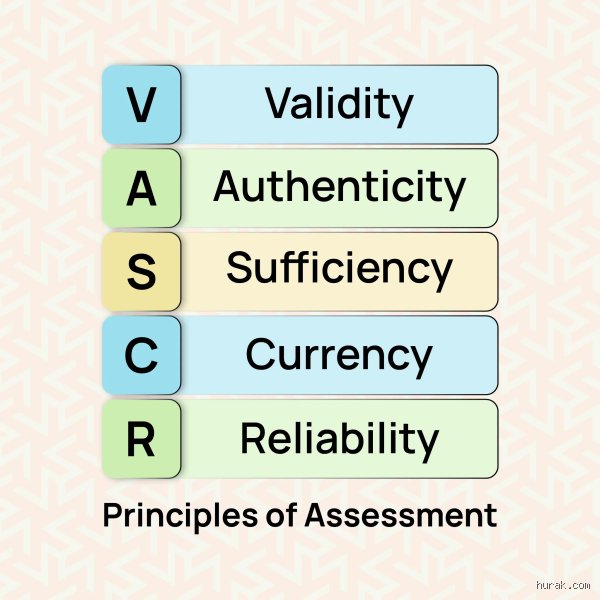
What are we actually talking about when we discuss these frameworks? Frankly, experts disagree on the exact hierarchy of these metrics, and honestly, it's unclear whether a perfect balance is even achievable in a chaotic, real-world classroom. Some theorists argue that validity trumps everything else, while others insist that without reliability, your entire data set is completely useless. I believe that treating these ideas as a rigid checklist is exactly how school boards end up buying expensive, standardized software packages that don't actually help teachers understand what their students know.
The Real-World Cost of Assessment Failure
Consider the notorious 2014 grading crisis in the United Kingdom, where a flawed algorithmic modification to the A-Level scoring system artificially deflated the marks of thousands of high-achieving public school students while preserving the scores of private school peers. That changes everything. It proved that when the architecture of evaluation lacks transparent fairness and flexibility, the human cost is measured in rejected university applications and shattered confidence. People don't think about this enough when they are designing administrative rubrics on a Sunday night.
Technical Breakdown Part One: The Twin Pillars of Validity and Reliability
Let us look at the heavy hitters of the evaluation world. Validity is the absolute cornerstone of any defensible testing strategy because it demands that an instrument measures exactly what it claims to measure, meaning you cannot give a reading comprehension test that is secretly disguised as a geometry exam. But where it gets tricky is ensuring that your test items don't accidentally measure reading speed or English language proficiency instead of the actual subject matter. Hence, a perfectly designed physics test can easily become invalid if the word problems require a deep understanding of American baseball terminology that an international student has never encountered.
The Statistical Tightrope of Consistent Results
Then comes reliability, the frustrating twin that demands absolute consistency. If a cohort of students takes a specific evaluation on a rainy Tuesday morning in Seattle, they should theoretically achieve the exact same statistical distribution of scores if they retook an equivalent version on a sunny Thursday afternoon in Miami. But how do we maintain this standard when human graders are inherently subjective creatures? A grader who hasn't had their morning coffee will naturally score an essay more harshly than someone reading the same paper right after lunch (a phenomenon well-documented in behavioral economics). To combat this, large-scale systems use inter-rater reliability coefficients, aiming for a Kappa statistic above 0.80 to ensure fairness.
The Inherent Friction Between Consistency and Truth
Here is my sharp opinion that contradicts the conventional wisdom: maximizing reliability often ends up destroying validity entirely. Because human thought is messy and unpredictable, making a test highly reliable usually means reducing it to multiple-choice questions that are easy to machine-grade. As a result: you get highly consistent data about things that don't actually matter, like rote memorization, while completely missing the complex problem-solving skills that employers actually value. We are far from achieving a perfect synthesis here.
Technical Breakdown Part Two: Fairness and Authenticity in the Age of Artificial Intelligence
Fairness means providing every single learner with an equitable opportunity to demonstrate their competence, which is vastly different from giving everyone the exact same test under the exact same conditions. If a student with severe dyslexia is forced to take a timed, text-heavy history exam without accommodations, the results do not reflect their historical knowledge; they reflect their processing speed. Because true equity requires us to dismantle these hidden barriers, modern curriculum designers are turning to Universal Design for Learning frameworks to bake accessibility directly into the initial design phase.
Bridging the Gap Between School and the Real World
Authenticity requires that tasks mimic the actual challenges found in professional or civic life. Why are we still forcing college students to write blue-book essays about corporate strategy when a real-world executive would write a concise memo or deliver a pitch deck? In 2022, a progressive nursing program in Melbourne, Australia, replaced 40% of their traditional pharmacology exams with simulated clinical handoffs. This shift forced students to communicate critical patient data under pressure—a move that dramatically improved their clinical readiness. That is what are the six principles of assessment look like when applied with actual imagination.
Evaluating Alternative Evaluation Frameworks Against the Classic Model
Many contemporary educators are completely abandoning traditional grading systems in favor of portfolio-based or narrative assessments. The argument is simple: the classic six principles were designed for an industrial era that prioritized compliance over creativity. Except that when you remove standardized benchmarks entirely, you often open the door to immense implicit bias, as teachers may unconsciously give better narrative reviews to students whose personalities match their own. In short, the traditional criteria provide a necessary, if flawed, shield against pure subjectivity.
The Rise of Competency-Based Progression
Look at the Western Governors University model, which allows students to progress as soon as they prove mastery of a specific skill, regardless of how many hours they sit in a lecture hall. This approach completely redefines the concept of sufficiency by focusing on competency rather than seat time. But can this scale to early childhood education or highly theoretical disciplines? The data is still mixed, and many traditional universities remain deeply skeptical of abandoning standard credit hours.