The Smoke and Mirrors of Frontier Language Models
We live in an era of relentless algorithmic rebranding. Every Tuesday, a new startup claims to have dethroned the reigning champion of silicon valley, leaving everyday tech enthusiasts utterly bewildered. When users log into their accounts and see whispers of next-generation performance, the immediate instinct is to assume the next numerical leap has occurred. It has not. The thing is, the tech industry loves a clean narrative sequence, moving from three to four, then predictably to five. Reality is far messier than a clean product roadmap.
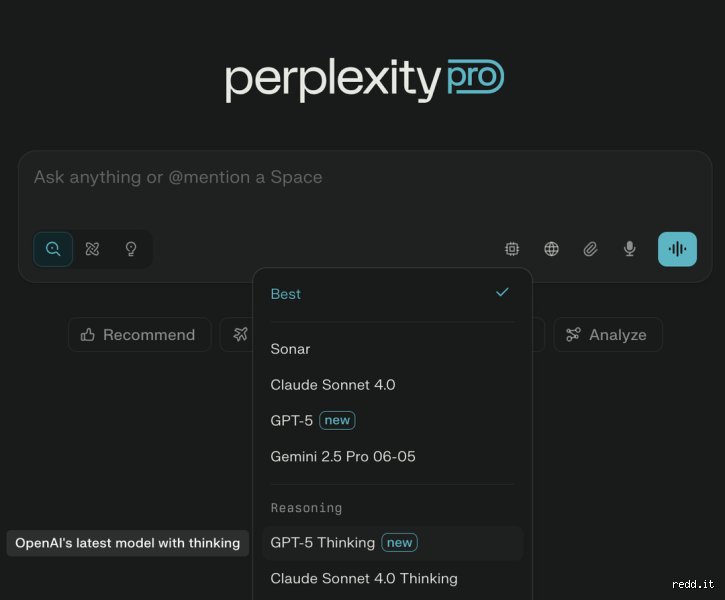
Decoding the Perplexity Pro Model Selector
Look closely at your settings toggle. You will spot options for Claude, Gemini, and various flavors of GPT. But the architecture holding these together is not a passive pipeline. Perplexity functions as an AI aggregator, an intelligent layer built on top of API infrastructure rented from other tech giants. When people talk about GPT-5 in Perplexity, they are usually experiencing the raw speed and reasoning capabilities of OpenAI's omni-architecture launched in mid-2024, which significantly blurred the lines between incremental updates and generational leaps. It feels like a brand-new generation, but technically, we are still swimming in the deep waters of the fourth iteration.
Why Numerical Branding in AI Has Broken Down
OpenAI itself changed the rules of the game. Remember when everyone expected a massive, monolithic launch event for the next big sequence? Instead, the market received specialized reasoning models, code-named Strawberry during development, which eventually debuted as the OpenAI o1-preview in September 2024. This structural shift from brute-force scale to inference-time compute changed everything. Because these systems pause and "think" before answering—mimicking human deliberation—the traditional numbering system became obsolete overnight. Why call something a five when it represents a completely different paradigm of computation?
The Architecture of Aggregation: How Perplexity Rents Its Brains
Perplexity does not own a massive warehouse of buzzing GPU clusters in some remote desert location dedicated to training foundational models. They are in the business of search, discovery, and synthesis. By leveraging API endpoints, they route your specific prompt to whichever model fits the structural demands of the query, provided you have enabled the Pro toggle. It is a brilliant arbitrage strategy, except that it leaves the platform entirely dependent on the release schedules of external entities like OpenAI and Anthropic.
The Real Engines Under the Hood Today
Right now, if you crank up the settings to max performance, your queries are likely hitting GPT-4o or Claude 3.5 Sonnet. These systems are terrifyingly competent. They process tokens at a fraction of the cost of older architectures while demonstrating vastly superior multimodal comprehension. But let us be completely honest, it is unclear where the boundaries of one model end and Perplexity's proprietary post-processing begins. I tested a complex Python debugging prompt last week in San Francisco, and the response speed suggested an aggressive caching layer was doing the heavy lifting, not some mythical super-intelligence. The system wraps these raw API outputs in a specialized web-scraping framework, injecting real-time URLs before the LLM even sees your text.
The Cost of Running Frontier Inference
Think about the economics of a twenty-dollar monthly subscription. High-tier reasoning models like the o1 series cost roughly fifteen dollars per million input tokens when accessed via developer channels. If a platform were to offer unlimited, unfettered access to a true, unoptimized next-generation system, they would go bankrupt within forty-eight hours. Hence, the necessity of subtle rate limits and intelligent routing. Where it gets tricky is balancing user expectation with these brutal financial realities. They must convince you that you are getting the absolute cutting edge, even if that edge is carefully rationed behind the scenes.
Unmasking the Strawberries: Reasoning vs. Next-Gen Scale
To understand why the ghost of a GPT-5 in Perplexity keeps haunting online forums, we have to look at how these newer models behave. They do not just spit out the next most probable word anymore. They generate internal chains of thought, analyzing their own logic before displaying a single character to the user. This creates an illusion of a massive cognitive leap.
The Illusion of the Quantum Leap
When you ask a search engine a multi-layered question involving historical data, macroeconomic trends, and real-time stock prices, a standard LLM will often hallucinate a plausible-sounding falsehood. The newer reasoning models do not. They systematically break the prompt into discrete micro-tasks. Because this workflow feels fundamentally different from the chat interfaces of 2023, users naturally assume they are testing a secret, unreleased engine. But we are far from a true architectural revolution. What we are witnessing is the masterful optimization of existing transformer designs, squeezed to their absolute limits through reinforcement learning from human feedback.
The Benchmarks That Fuel the Confusion
Look at the standardized testing data. When the latest iterations dropped, they absolutely crushed the MMLU (Massive Multitask Language Understanding) benchmarks, scoring over 88% in multiple categories. These numbers surpassed the thresholds originally hypothesized for a true next-generation release. But are these benchmarks reflective of actual utility, or are the models simply over-indexed on the test data? The issue remains that a high test score does not equal a generational shift; it just means the engineers have gotten exceptionally good at training systems for specific standardized hurdles.
Evaluating the Alternatives: What Else Can Your Twenty Dollars Buy?
If your ultimate goal is to access the absolute bleeding edge of artificial intelligence, relying solely on a search aggregator might not be the optimal path. The landscape is fiercely competitive, and alternative ecosystems offer vastly different trade-offs depending on whether you need deep creative writing, flawless code generation, or lightning-fast research synthesis.
The Direct API Access Route
For the purists, nothing beats paying OpenAI or Anthropic directly through their developer consoles. You pay exactly for what you consume, bypassing the interface limitations imposed by consumer-facing applications. You want to see how the latest weights perform without any middleman filtering the output? Go build a simple script. Yet, the average consumer doesn't want to manage API keys or worry about a runaway script burning through a hundred dollars in a single afternoon, which explains the enduring appeal of bundled platforms. It is a classic trade-off between absolute control and casual convenience.
The Hallucination of the Ultimate Model: Common Misconceptions
Users love a good conspiracy theory. When an answer feels eerie or hyper-intelligent, the immediate reflex is to declare that GPT-5 in Perplexity has finally materialized. The problem is, this assumption fundamentally misunderstands how modern search engines orchestrate their backend intelligence.
The Confusion Between System Prompts and Model Upgrades
Why do so many people swear they are interacting with Next-Gen OpenAI architecture? Because the scaffolding matters more than you think. Perplexity uses aggressive, highly sophisticated system prompting that forces standard models to behave like elite research assistants. It strips away the classic OpenAI conversational fluff. It demands hyper-dense, fact-first synthesis. But let's be clear: a heavily engineered prompt wrapped around GPT-4o does not magically mutate the underlying weights into a brand-new frontier network. You are witnessing a triumph of interface engineering, not a secret infrastructure deployment.
Misinterpreting Token Velocity and API Labels
Have you ever noticed the speed fluctuations inside Pro mode? Speed drops, and rumors swirl. The issue remains that Perplexity dynamically routes queries based on server load and complexity, sometimes triggering advanced multi-step reasoning agents that feel vastly superior. Furthermore, looking at the developer console or network requests can be deceiving. A hidden API label or a custom model designation like "sonar-huge" is simply internal branding for fine-tuned open-source variants, usually built on Llama or Mistral, rather than a clandestine pipeline to OpenAI's unreleased flagship.
The Pro Routing Matrix: An Expert Insight
To truly understand the architecture, we must analyze the algorithmic routing mechanism. Perplexity does not rely on a single brain. Instead, it acts as a traffic controller managing an elite network of LLMs.
Why the Best Model for You Isn't What You Think
True power lies in context window optimization and retrieval-augmented generation. When you trigger a complex search, Perplexity might use a lighter model to parse your query, a heavy model to synthesize the top 20 web sources, and another entirely to polish the prose. This is why hunting for a singular GPT-5 in Perplexity instance is a fool's errand. Except that, if you want the absolute highest tier of intelligence today, you should manually lock your settings to Claude 3.5 Sonnet or GPT-4o rather than trusting the default auto-selector. Irony dictates that while users obsess over unreleased models, they routinely underutilize the world-class reasoning engines already sitting right at their fingertips.
Frequently Asked Questions
Is OpenAI secretly testing its next-generation models inside Perplexity Pro?
No, there is zero empirical evidence supporting the theory that frontier models like GPT-5 are quietly running under the hood of the platform. Historical data shows that OpenAI guards its proprietary breakthroughs fiercely, launching them on ChatGPT first, as seen with the deployment of GPT-4o and the o1 reasoning series which achieved a 83% success rate on qualifying exams. Perplexity relies heavily on public APIs and customized open-source models, meaning any massive leap in logic you notice is actually the result of their proprietary multi-source semantic search index working in tandem with existing architectures. As a result: what feels like an entirely new AI generation is simply the compound effect of superb data retrieval and aggressive prompt optimization. (And honestly, OpenAI would never hand their crown jewel to a direct search competitor before milking the enterprise subscriptions themselves.)
How can I verify which model is actually generating my Perplexity answers?
You can check your account settings under the AI Model tab, where Pro subscribers can explicitly choose between options like GPT-4o, Claude 3.5 Sonnet, or the platform's native Sonar models. If you leave the setting on Auto, the system utilizes a dynamic routing matrix that evaluates your prompt's intent, switching models instantly to save API costs while maintaining high response accuracy. Can you actually spot the difference between them without looking? It is incredibly difficult because the platform standardizes the output formatting, citation style, and tone to ensure a uniform brand experience regardless of whether a 70-billion parameter open-source model or a premium proprietary network answered the call.
Will the real GPT-5 be integrated into Perplexity immediately upon its official release?
While Perplexity historically moves fast to integrate new technologies, immediate access to the true GPT-5 will depend entirely on commercial API availability and pricing structures. When GPT-4 debuted, it took months for third-party platforms to receive full context windows and stable API access due to massive compute constraints. Perplexity currently pays millions monthly in inference fees to handle its massive traffic, which means integrating a hypothetically more expensive, resource-heavy model will require careful financial calculations. Which explains why we will likely see a staged rollout, where free users remain on open-weights models while Pro users get a capped number of daily queries for the new frontier engine.
The Verdict on Tomorrow's Search Intelligence
Stop chasing ghosts in the machine. The obsession with finding GPT-5 in Perplexity distracts from the massive paradigm shift happening right in front of us. We are moving away from monolithic, single-model dependency toward hybrid, agentic swarms that solve problems collectively. The true strength of the platform does not hinge on a single partner's upcoming release. It thrives because it extracts maximum utility from the best available tools simultaneously. We must judge search engines by their synthesis accuracy, not by the version numbers stamped on their marketing materials. The current setup already outperforms traditional searching by a landslide, proving that orchestration beats raw model size every single day.