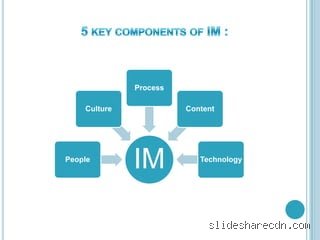
The Messy Reality Behind Defining Information Management Today
Let us look at how we got here. Information management is not merely a fancy synonym for IT support or cloud backup solutions, though many legacy executives still mistakenly treat it that way. Actually, it is the systematic oversight of an organization's total knowledge portfolio across its entire operational timeline. Think of it as constructing a high-speed railway system for digital assets where the tracks, the signaling, and the switching stations must function perfectly together. When Equifax suffered its notorious data breach in September 2017, the failure was not a lack of expensive firewall technology; it was a fundamental breakdown in basic asset visibility and patch management protocols.
The Disconnection Between Raw Data and Genuine Enterprise Knowledge
Where it gets tricky is drawing the line between raw data points and actionable business intelligence. A single timestamped transaction log from a retail point-of-sale terminal in Vienna is just a digital footprint. But what happens when you aggregate three million of those footprints? That changes everything. Information management transforms those isolated numbers into predictable supply chain forecasting models. Except that most companies spend 80% of their time simply wrangling raw formats rather than extracting actual commercial value from them.
Why the Classic Three Vs of Big Data No Longer Suffice
For over a decade, consultants hammered the ideas of volume, velocity, and variety into our heads. But honestly, it is unclear why we still pretend those metrics capture our current operational reality. The issue remains that we are drowning in sheer volume while starving for verifiable accuracy. Because who cares if you can process fifty thousand events per second via Apache Kafka if half of those inputs contain corrupted strings or duplicate customer profiles? We need to pivot our focus toward veracity and systemic trust.
Component 1: Ingestion Architecture and the Chaos of Data Acquisition
The journey begins at the edge. Data ingestion architecture represents the frontline defense where unstructured, semi-structured, and structured inputs crash into your enterprise ecosystem. Whether you are dealing with real-time IoT sensor telemetry from a factory floor in Stuttgart or batch-processing legacy mainframes overnight, this component dictates the ultimate health of downstream analytical pipelines. People don't think about this enough: if your ingestion layer lacks dynamic schema validation, you are essentially importing operational chaos directly into your core business systems.
The Eternal Struggle: Real-Time Streaming vs. Traditional Batch ETL
Imagine trying to drink water from a firehose while simultaneously archiving old newspapers. That is the exact challenge facing modern engineering teams. Extract, Transform, Load (ETL) protocols have historically formed the bedrock of corporate reporting, running silently during midnight maintenance windows. Yet, the modern market demands instant feedback loops. As a result: streaming platforms like Apache Flink or Confluent Kafka have become standard requirements for fraud detection setups, which explains why legacy financial institutions are spending billions rewriting their foundational ingestion layers to support sub-millisecond event processing.
API Management and the Perils of Third-Party Dependency
But how do you handle external variables? Modern enterprises rely on hundreds of external APIs for weather feeds, market pricing, and demographic analytics. This brings us to a precarious point. What happens when an external vendor alters their JSON payload structure without warning at three in the morning? Unless your ingestion component utilizes automated API contract testing, your entire dashboard ecosystem collapses instantly, proving that acquisition is as much about external governance as it is about internal plumbing.
Component 2: Structured Storage Ecosystems and Hybrid Cloud Realities
Once you capture the data, you have to put it somewhere safe, accessible, and cost-efficient. The storage infrastructure component has evolved into a complex hybrid matrix spanning local data centers, public cloud providers, and decentralized edge environments. It is no longer a simple choice between buying more physical hard drives or spinning up an AWS S3 bucket. Organizations now navigate sophisticated tiered storage topologies where data automatically migrates between hot, warm, and cold tiers based on real-time retrieval demands.
Breaking Down the Great Architectural Divide: Data Lakes vs. Data Warehouses
This is where corporate IT departments frequently wage ideological wars. Data warehouses, typified by platform architectures like Snowflake or Google BigQuery, require strict, pre-defined schemas that make them incredibly fast for running traditional SQL queries. Conversely, data lakes store raw files in their native formats without initial optimization. But we are far from a consensus on which approach reigns supreme. The industry has recently gravitated toward a hybrid Data Lakehouse architecture, attempting to marry the structural discipline of warehouses with the cheap, infinite storage capacity of cloud object stores.
The Financial Trap of Cloud Egress Fees
Let us talk about the money side because cloud vendors love to gloss over this part. Storing five petabytes of historical log data in the cloud seems remarkably inexpensive on paper, often costing just a fraction of a cent per gigabyte each month. But wait until you actually try to move that data across cloud regions or extract it back to your on-premises analytics environment for a specialized machine learning project. The unexpected egress bills can easily cripple an annual IT operations budget in a matter of days, making storage architecture as much a financial strategy as a technical one.
Evaluating Modern Analytical Approaches Against Traditional Relational Databases
To truly understand how these architectural choices impact day-to-day enterprise performance, we must contrast modern distributed analytical frameworks with the classic relational database management systems that dominated the corporate landscape for decades. The operational differences are profound, shaping how companies design their teams and allocate their capital resources.
The Relational Model: Predictability and ACID Compliance
Traditional setups rely on strict relational databases like PostgreSQL or Oracle. These systems excel at transaction processing because they enforce absolute data integrity through ACID compliance (Atomicity, Consistency, Isolation, Durability). If a bank transfers money between accounts in Zurich, the system guarantees that the debit and credit happen simultaneously or not at all. However, these systems scale vertically, meaning you eventually need to buy a bigger, exponentially more expensive server to handle increased workloads.
The Distributed Analytical Alternative: Horizontal Scaling and NoSQL Flexibility
Modern information management frequently bypasses relational constraints to embrace distributed setups like Cassandra, MongoDB, or regional Google Spanner deployments. These systems scale horizontally by distributing fragments of data across hundreds of commodity servers located worldwide. You lose the absolute, immediate consistency of traditional systems—settling instead for eventual consistency—but you gain the ability to process global-scale datasets without experiencing single points of system failure. Is the trade-off worth it? For a global logistics company tracking millions of active shipments simultaneously, the answer is an absolute yes.
Common Information Management Pitfalls and Myths
The Illusion of the Digital Junkyard
Many organizations behave like digital hoarders. They assume hoarding every petabyte of raw data automatically yields operational brilliance, but that is a hallucination. Storing chaotic files without strict categorization creates an expensive digital junkyard. Look at the data: recent industry studies show that over 55 percent of corporate data is dark data, meaning it is collected, processed, and stored but never actually utilized. We must acknowledge that volume does not equal value. The problem is that junk in means junk out, regardless of how slick your modern cloud infrastructure looks.
Technology is a Savior Complex
Buying a multi-million dollar software suite will not miraculously repair broken corporate workflows. Executives routinely fall into this trap because buying software feels like immediate progress. Let's be clear: a tool only amplifies existing habits. If your communication culture is toxic, a new enterprise platform merely accelerates that internal chaos. Because a shiny user interface cannot write your compliance protocols or force lazy teams to tag metadata accurately. It requires human behavioral transformation, which explains why so many digital overhauls collapse under their own weight.
Security as an Afterthought
Organizations frequently treat information management like a static filing cabinet. They protect the perimeter but ignore how internal assets circulate. But true security must be baked into the architecture from day one. When companies isolate security into a separate department, data vulnerabilities skyrocket. Is it really surprising that unauthorized internal access accounts for a massive slice of annual data breaches?
The Hidden Leverage: Cognitive Friction Reduction
Designing for the Human Subconscious
Let us pivot to a highly sophisticated dimension of this discipline: the deliberate reduction of cognitive friction for your workforce. Expert systems design should focus less on theoretical database perfection and far more on how a tired human brain navigates an interface at four in the afternoon. When employees encounter clunky search functions, they immediately bypass official channels. As a result: they resort to saving classified project files on personal desktop folders or insecure messaging apps. This shadow IT behavior creates catastrophic regulatory blind spots. A intuitive taxonomy decreases search times by 35 percent, which directly transforms daily operational velocity. We must design data pathways that mimic natural human intuition rather than forcing workers to think like rigid algorithms. (And yes, your current complex folder structure is probably causing your team secret misery.)
Frequently Asked Questions
Does robust information management require a dedicated Chief Data Officer?
While small enterprises can survive by distributing these responsibilities across existing IT leadership, scaling past mid-market territory makes a centralized leader mandatory. Statistical tracking indicates that corporations employing a dedicated CDO achieve 2.5 times higher data utilization rates than those without centralized oversight. The issue remains that generalist technology executives often prioritize infrastructure uptime over semantic data quality. Recruiting a specialized executive bridges the gap between raw computing power and profitable business intelligence. In short, the investment yields measurable dividends by preventing costly compliance failures and accelerating analytics projects.
How does modern regulatory compliance impact daily storage strategies?
Global frameworks like GDPR and CCPA have permanently transformed corporate data handling from a passive activity into an active legal minefield. Organizations can no longer indefinitely retain consumer records without explicit justification. Non-compliance carries devastating financial penalties, with global regulatory bodies issuing billions in cumulative fines over recent evaluation cycles. Consequently, modern information management strategies must incorporate automated purging schedules that permanently erase redundant consumer records. This proactive scrubbing minimizes legal exposure while simultaneously reducing your ongoing cloud hosting expenses.
Can artificial intelligence completely automate the tagging of corporate assets?
AI algorithms excel at processing vast quantities of unstructured text to apply preliminary metadata tags at scale. Yet, total reliance on automated systems introduces significant classification errors due to context blindness. Machine learning tools frequently misinterpret industry jargon or nuanced internal code names, which leads to corrupted search indexes. Human oversight remains mandatory to audit the algorithmic outputs and refine the underlying taxonomy rules. Think of automation as a powerful engine that still requires a skilled human pilot to navigate complex corporate realities.
The Verdict on Data Sovereignty
Treating organizational knowledge as a passive IT asset is a recipe for corporate obsolescence. We live in an era where data hoarding is cheap, but cognitive clarity is exceptionally rare. True competitive advantage belongs exclusively to leadership teams that actively ruthlessly prune their digital ecosystems. Winners build architectures around human behavioral patterns rather than idealistic engineering frameworks. Except that achieving this state requires abandoning the comfortable myth that technology solves cultural laziness. Commit to rigorous information governance today, or prepare to watch your market share slowly evaporate into the digital noise.
💡 Key Takeaways
- Is 6 a good height? - The average height of a human male is 5'10". So 6 foot is only slightly more than average by 2 inches. So 6 foot is above average, not tall.
- Is 172 cm good for a man? - Yes it is. Average height of male in India is 166.3 cm (i.e. 5 ft 5.5 inches) while for female it is 152.6 cm (i.e. 5 ft) approximately.
- How much height should a boy have to look attractive? - Well, fellas, worry no more, because a new study has revealed 5ft 8in is the ideal height for a man.
- Is 165 cm normal for a 15 year old? - The predicted height for a female, based on your parents heights, is 155 to 165cm. Most 15 year old girls are nearly done growing. I was too.
- Is 160 cm too tall for a 12 year old? - How Tall Should a 12 Year Old Be? We can only speak to national average heights here in North America, whereby, a 12 year old girl would be between 13
❓ Frequently Asked Questions
1. Is 6 a good height?
2. Is 172 cm good for a man?
3. How much height should a boy have to look attractive?
4. Is 165 cm normal for a 15 year old?
5. Is 160 cm too tall for a 12 year old?
6. How tall is a average 15 year old?
| Male Teens: 13 - 20 Years) | ||
|---|---|---|
| 14 Years | 112.0 lb. (50.8 kg) | 64.5" (163.8 cm) |
| 15 Years | 123.5 lb. (56.02 kg) | 67.0" (170.1 cm) |
| 16 Years | 134.0 lb. (60.78 kg) | 68.3" (173.4 cm) |
| 17 Years | 142.0 lb. (64.41 kg) | 69.0" (175.2 cm) |