The Evolution of Measuring Minds: Where It Gets Tricky
We have engineered a world obsessed with measurement. The thing is, historical records show our ancestors were just as preoccupied with sorting individuals, though their methods would make modern psychometricians shudder. Consider the Imperial Chinese civil service examinations, initiated during the Han Dynasty around 165 BCE, which subjected candidates to days of grueling essay writing locked in isolated cells. It was brutal. Yet, it established a meritocratic precedent: the belief that a structured tool could objectively gauge human capability. Fast forward to 1905, when Alfred Binet debuted the first practical intelligence scale in Paris to identify students needing alternative assistance, and the modern apparatus was truly born.
From Rote Recall to Complex Competencies
For decades, the default mechanism relied on passive reproduction. You sat in a wooden desk, stared at a mimeographed sheet, and bubbled in A, B, or C. But human intelligence refuses to be neatly cornered by a graphite pencil. Because cognitive science underwent a massive shift in the late twentieth century, the definition expanded to encompass authentic tasks—simulations, portfolios, and viva voces that mirror real-world chaos. Honestly, it is unclear whether our current digital rubrics are genuinely capturing genius or just creating more sophisticated hoops to jump through, but the shift from memorization to application remains undeniable.
The Semantic Trap: Testing Versus Evaluation
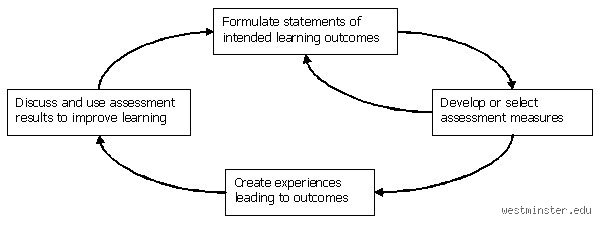
People don't think about this enough: a test is merely a single snapshot, a solitary instrument in a vast toolkit. Evaluation, on the other hand, sits at the macro level, passing judgment on entire institutional programs or national curricula based on aggregated data. The concept of assessment bridges this gap by focusing on the individual's journey, transforming raw numbers into actionable narratives. It is the connective tissue between teaching and knowing.
The Functional Anatomy of Educational Scrutiny
To truly dissect the concept of assessment, one must separate the engine into its primary moving parts. We traditionally split the domain into two warring, yet symbiotic, factions: formative and summative. The former happens during the messy process of acquisition, while the latter waits at the finish line with a rubber stamp. Think of it like a chef tasting the soup versus the customer eating it. That changes everything about how the data is utilized.
Formative Mechanics and the Power of Low Stakes
Imagine a high school chemistry class in Boston attempting to master stoichiometry. The instructor utilizes exit tickets—brief, ungraded questions handed in at the door—to gauge comprehension before the period ends. This is formative practice in its purest state. It is diagnostic, agile, and remarkably forgiving. As a result: teachers pivot their lesson plans in real-time, catching misconceptions before they ossify into permanent failures. Experts disagree on the optimal frequency of these interventions, but the psychological benefits of removing the threat of a failing grade are monumental for student engagement.
Summative Judgments and the High-Stakes Reality
But then comes the hammer. Summative evaluation arrives in the form of the SAT, the International Baccalaureate finals, or the Gaokao in China, where millions of futures hang in the balance of a single afternoon. These are standardized, norm-referenced monsters designed to sort, rank, and filter. The issue remains that while summative metrics offer the clean, comparable data points that politicians and university admissions officers crave, they frequently induce paralyzing anxiety and encourage teaching to the test. It is a necessary evil that often hollows out the joy of discovery.
Ipsative Tracking: The Forgotten Alternative
There is a third option that rarely gets the spotlight it deserves. Ipsative measuring compares a performer's current output solely against their own past performance, completely ignoring peer averages or rigid external benchmarks. It is how video games track progress, pushing you to beat your own high score. Why don't we use this more in formal schooling? I believe our refusal to institutionalize this self-referential model reveals that our systems value compliance and comparison far more than actual personal growth.
Psychometric Integrity: Reliability, Validity, and Fairness
If you are going to construct a mechanism that dictates human destiny, the underlying math needs to be bulletproof. This is where psychometrics—the science of psychological measurement—enters the fray. A flawed instrument is worse than no instrument at all, acting as a distorted mirror that misleads both the guide and the traveler. Two pillars uphold the entire structure, yet they are constantly in tension.
The Elusive Quest for True Validity
Does the instrument actually measure what it claims to measure? That is the core question of validity. If a standard fifth-grade math word problem requires an elite vocabulary to decipher, it is no longer just measuring mathematical competence; it has mutated into a reading comprehension test. Which explains why so many historical datasets are fundamentally compromised. Construct irrelevant variance—the technical term for this kind of noise—creeps into the most carefully designed rubrics, invalidating the outcomes and misallocating educational resources.
Reliability: The Consistency Imperative
Then there is reliability, the requirement that an instrument yields identical results across different days, environments, and graders. If a student takes a standardized test on a rainy Tuesday in Seattle and scores a 92%, they should not score a 74% on a sunny Thursday in Miami under the same conditions. Achieving inter-rater reliability—where two separate human examiners look at the same open-ended essay and award the exact same score—is notoriously difficult, often requiring hours of calibration that institutions desperately try to automate with algorithms.
The Great Divergence: Criterion-Referenced Versus Norm-Referenced Systems
How we interpret the final score depends entirely on the philosophical framework of the architecture. The concept of assessment splits cleanly down the middle here, forcing creators to choose between absolute mastery and relative ranking. It changes how we view human potential.
Driving Tests Versus the Bell Curve
A criterion-referenced model checks your performance against a fixed set of predetermined tasks. Think of a standard driver's license examination: if you park correctly, obey the speed limit, and do not crash, you pass. It does not matter if the applicant before you was an F1 driver or a total klutz. You are judged against the criteria, period. Norm-referenced systems, conversely, are built upon the architecture of the Gaussian bell curve. Here, your success is entirely dependent on the failure of others. If you score a 95% but everyone else scores a 98%, you are relegated to the bottom tier. We're far from it being a fair reflection of individual capability, yet this competitive ranking remains the engine of elite university selection globally.