Remember when Apache Hadoop was the shiny new toy back in 2011? We thought we had a handle on scale back then, but the landscape shifted beneath our feet. Today, the sheer existential dread of managing petabytes of unstructured text, chaotic sensor logs, and streaming video has forced us to redraw the analytical map. We are no longer just looking at a massive pile of hard drives; instead, we are grappling with an ecosystem that feels almost alive, volatile, and occasionally hostile. Honestly, it's unclear if half the organizations bragging about their data lakes even know what is buried in the muck at the bottom of them. I argue that the traditional definition of big data is entirely obsolete without factoring in modern security risks and structural fluidity.
The Evolution of Modern Information Infrastructure: Moving Past the Traditional Framework
The original triumvirate of data management—conceived by analyst Doug Laney in 2001—focused strictly on how much stuff you had, how fast it arrived, and how messy it looked. It was a neat, clean packaging job for boardrooms. But the enterprise landscape mutated rapidly. By the time the global datasphere surged past 64 zettabytes in the early 2020s, those three pillars started buckling under the weight of real-world messiness, which explains why academics and practitioners scrambled to append new descriptors. We needed more letters, or rather, more specific definitions to capture the absolute madness of modern cloud environments.
Why Three Dimensions Failed to Capture the Chaos of the Digital Age
A narrow focus on size alone ignores the human element. What happens when your automated marketing pipeline ingests millions of duplicate bot clicks from a server farm in Frankfurt? The volume is impressive, sure, but the utility drops to zero. That changes everything because it forces engineers to ask qualitative questions rather than just buying more Amazon S3 storage buckets. The issue remains that corporate infrastructure became too fast for its own good, leaving traditional validation systems choking in the dust.
The Real-World Cost of Ignoring Deep Data Attributes
Let us look at the financial sector where a single millisecond of latency can trigger a catastrophic algorithmic trading loop. In May 2010, the infamous Flash Crash wiped out nearly a trillion dollars in market value within minutes, providing a brutal lesson in what happens when velocity outpaces system comprehension. It was a wake-up call that people don't think about this enough. Data isn't just oil; it is volatile organic chemistry, and treating it like a static asset is a fast track to ruin.
Deconstructing the Core Components: Scale, Speed, and Structural Diversity
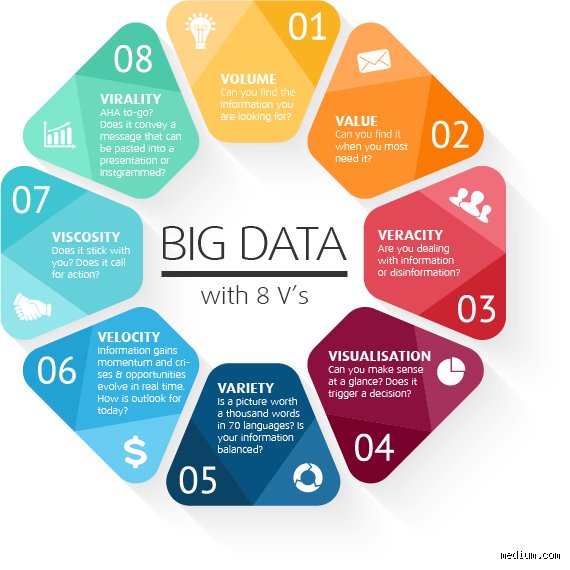
To grasp what are the 8 V's of big data, one must first dissect the physical traits of the information itself before worrying about its meaning. We start with Volume, the absolute physical footprint of the records stored across distributed networks. Think of the European Organization for Nuclear Research (CERN) producing roughly 1 zettabyte of information per year from Hadron Collider experiments—it is an unimaginable mountain of bits. Yet, scale is nothing without Velocity, which defines the processing rate of incoming streams, like Uber tracking thousands of concurrent GPS coordinates globally every single second.
The Nightmare of Structural Chaos and the Variety Matrix
Where it gets tricky is Variety. Gone are the days when everything fit neatly into SQL tables with predictable rows and columns. Now, a typical healthcare provider like the Mayo Clinic has to synthesize structured billing codes with highly unstructured data: doctor's scribbled notes, high-resolution MRI scans, genomic sequencing pipelines, and real-time heart rate monitor feeds. Managing this requires entirely different database architectures, moving from relational engines to NoSQL solutions like MongoDB or graph databases like Neo4j. But wait, can we actually trust any of this fragmented information?
The Constant Fight Against Noise and Stream Decay
This leads us straight into the jaw of Veracity, the trustworthiness and quality of the ingested material. If your telemetry data from a fleet of Boeing 787 aircraft contains corrupted packets caused by high-altitude atmospheric interference, your predictive maintenance algorithms will spit out garbage. A lot of data scientists spend up to 80 percent of their time simply cleaning up these anomalies, an exhausting process of digital janitorial work that costs global industries billions annually. We're far from automated perfection here.
Economic Viability and Semantic Fluidity: The Contextual Attributes
The next layer of understanding what are the 8 V's of big data shifts from physical characteristics to economic and contextual realities. Consider Value, the ultimate justification for spending millions on enterprise infrastructure. Collecting records just for the sake of hoarding is a corporate disease—an expensive one at that. If Target cannot leverage its customer purchasing logs to accurately predict buying trends or optimize supply chains in Minneapolis, then those server racks are just expensive space heaters.
The Shape-Shifting Nature of Modern Information Ingestion
But how does meaning change over time? Enter Variability, which captures the shifting meanings and inconsistent speeds of data flows. This is completely distinct from variety. Think about social media sentiment analysis during the Super Bowl; a word like "sick" can mean terrible during a medical emergency, but it means incredible when a quarterback throws a 60-yard touchdown pass. Context changes constantly, and your natural language processing models must adapt on the fly, or they become instantly irrelevant.
The Paradox of Meaningful Business Intelligence
Experts disagree on whether value can ever be truly measured before the analysis is finished. Can you really quantify the worth of a dataset before you have even figured out what questions to ask it? It is a classic chicken-and-egg dilemma that keeps Chief Data Officers awake at night. Some data yields insights immediately, while other repositories sit dormant for a decade before a new algorithm unlocks their hidden patterns.
The Human Interface and the Security Imperative: Perception Meets Defense
We cannot discuss what are the 8 V's of big data without addressing how humans actually consume the insights and how organizations protect the perimeter. Visualization is the art and science of rendering billions of data points into something a human executive can comprehend within a five-minute briefing. Using tools like Tableau or complex Javascript libraries like D3.js, engineers build dashboards that compress high-dimensional space into clear charts. But a poorly designed graph is worse than no graph at all because it creates a false sense of certainty.
The Hidden Fragility of Massive Analytics Distributed Pipelines
Finally, we must confront Vulnerability, the darkest and most pressing aspect of modern data science. Large aggregations of sensitive information are nothing short of a homing beacon for cybercriminals. Look no some years back to the Equifax breach of 2017, where the personal details of over 147 million people were exposed due to a single unpatched Apache Struts vulnerability. When you centralize your information assets to perform deep analytics, you inadvertently create a catastrophic single point of failure. Security can no longer be an afterthought tacked onto the end of a deployment checklist—it has to be baked into the very fabric of the architecture.
Common mistakes and misconceptions around big data metrics
The obsession with the original volume trap
Many organizations paralyze their engineering teams by focusing exclusively on scale. They hoard petabytes of unstructured text, server logs, and obsolete telemetry because they believe sheer scale guarantees insight. The problem is that data hoarding without a strategy creates a digital landfill, not a goldmine. Let's be clear: a massive data lake filled with corrupted or unindexed records will actively drain your corporate budget through skyrocketing cloud storage fees while yielding exactly zero actionable insights.
Confusing real-time velocity with strategic value
Engineers love speed. Because of this bias, companies spend millions building low-latency streaming pipelines using Apache Kafka or Flink to process information in milliseconds. But does your quarterly marketing strategy honestly change based on a millisecond fluctuation in user behavior? No, it does not. Velocity is completely useless if your decision-making loop operates on a weekly cadence, making the hyper-fast infrastructure an expensive engineering vanity project rather than a business necessity.
Ignoring the hidden costs of data veracity
We blindly trust dashboards. Yet, data cleansing frequently consumes up to 80% of a data scientist's daily schedule because raw inputs are notoriously filthy. When you feed conflicting, biased, or unverified sensor information into an advanced machine learning model, the output is merely accelerated garbage. Organizations consistently underestimate the veracity-induced financial deficit, assuming that modern AI algorithms can magically smooth over missing variables and erratic telemetry fields.
The dark matter of information: Exploiting variability and volatility
Predictive orchestration via systemic variance
While everyone talks about volume, the true elite practitioners focus on how data structures mutate over time. Variability represents the shifting meaning of words and formats across different contexts, such as a spikes in social media slang during live broadcasting events. If your system cannot dynamically adjust its schema to accommodate these sudden linguistic or structural pivots, your analytical pipelines will break overnight. Managing this requires dynamic schema-on-read architectures that treat flux not as an annoying database error, but as a primary signal.
The shelf-life dilemma of data volatility
How long should information live before it becomes a liability? Data volatility dictates the precise moment data loses its predictive potency and transforms into expensive digital noise. For instance, high-frequency trading algorithms rely on market data that becomes entirely obsolete within 5 milliseconds. But why are you storing that exact same microscopic tick data in high-tier SSD storage three years later? Expert data architects enforce strict, automated lifecycle policies that aggressively purge or archive information based on its specific decay rate, which explains why top-tier tech firms minimize their active data footprint to maximize operational efficiency.
Frequently Asked Questions
Does the framework of the 8 V's of big data apply equally to small businesses?
Small enterprises frequently misinterpret the 8 V's of big data as an exclusive playground for multinational tech giants with massive budgets. The issue remains that while a local e-commerce store might generate only 15 gigabytes of customer interactions monthly, the principles of veracity and value are actually more critical for them because their margin for error is razor-thin. A single corrupted data stream can completely derail a localized marketing campaign, whereas a global corporation can easily absorb a 12% drop in analytical accuracy. Statistics show that small firms utilizing structured customer data frameworks experience a 24% higher operational efficiency gain compared to peers who ignore their modest data pools. In short, the scale changes, but the core architectural disciplines remain identical regardless of server size.
Which of the dimensions causes the highest percentage of project failures?
Industry data indicates that poor management of data veracity causes approximately 40% of all enterprise analytics failures globally. When data lineage is broken or undocumented, executives lose faith in the resulting reports, which leads to a total abandonment of the deployed business intelligence tools. This trust deficit is incredibly costly, especially since corporations lose an estimated 3.1 trillion dollars annually in the United States alone due to poor data quality issues. Except that organizations keep investing heavily in computing power rather than fixing their underlying data ingestion pipelines. As a result: systems fail because of trust issues rather than technical processing limitations.
How do modern regulatory frameworks like GDPR impact these data characteristics?
Global privacy regulations have thrown a massive wrench into the traditional mechanics of data volatility and volume. Under strict mandates like GDPR, you can no longer legally retain customer profiles indefinitely just because storage is cheap, meaning the lifespan of information must now be explicitly capped by design. Furthermore, the right to be forgotten forces database administrators to develop complex deletion scripts that can surgically remove individual nodes from massive, interconnected data lakes without disrupting the integrity of the overall graph. Because of these legal requirements, compliance has essentially transformed data management from an optional optimization strategy into a mandatory legal hurdle.
The algorithmic illusion: A definitive stance on data management
The tech industry remains dangerously infatuated with accumulation, yet hoarding petabytes of uncurated information is a symptom of strategic laziness rather than technological sophistication. We must stop treating the 8 V's of big data as a checklist for building larger digital warehouses, and instead view them as a strict framework for aggressive elimination. The ultimate winners in the digital economy will not be the corporations boasting the largest server clusters, but the teams that ruthlessly filter out the noise to isolate the signal. Are you building an asset, or are you just funding a very large, unreadable digital cemetery? True data maturity requires the courage to delete irrelevant information, the discipline to validate veracity before ingestion, and the wisdom to prioritize human-centric value over mindless computational scale.